
Bahdanau, D.; Cho, K.; and Bengio, Y. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
Boor, V.; Overmars, M. H.; and Van Der Stappen, A. F. 1999. The Gaussian sampling strategy for probabilistic roadmap planners. In Proceedings 1999 IEEE International Conference on Robotics and Automation (Cat. No. 99CH36288C), volume 2, 1018–1023. IEEE.
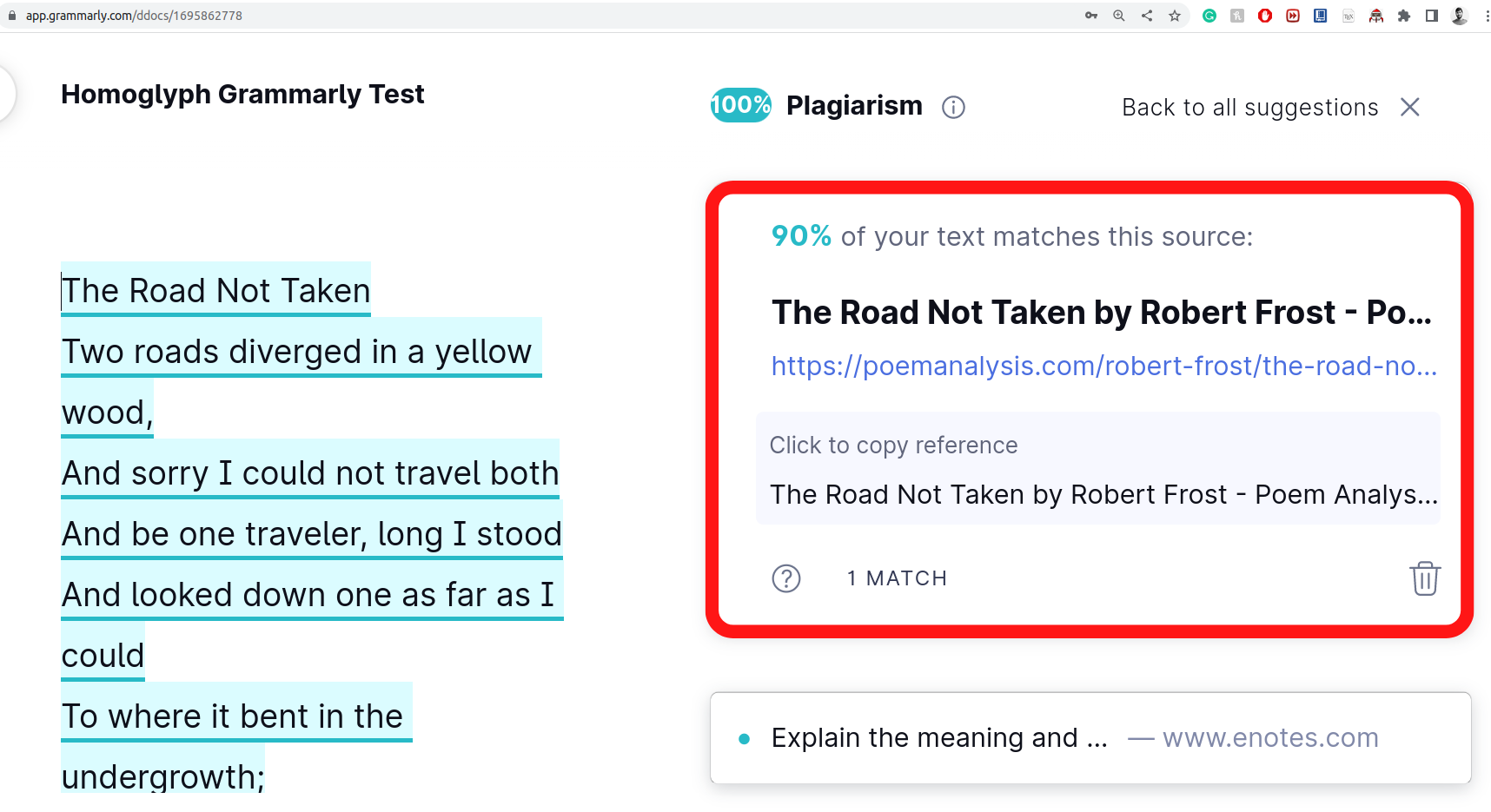
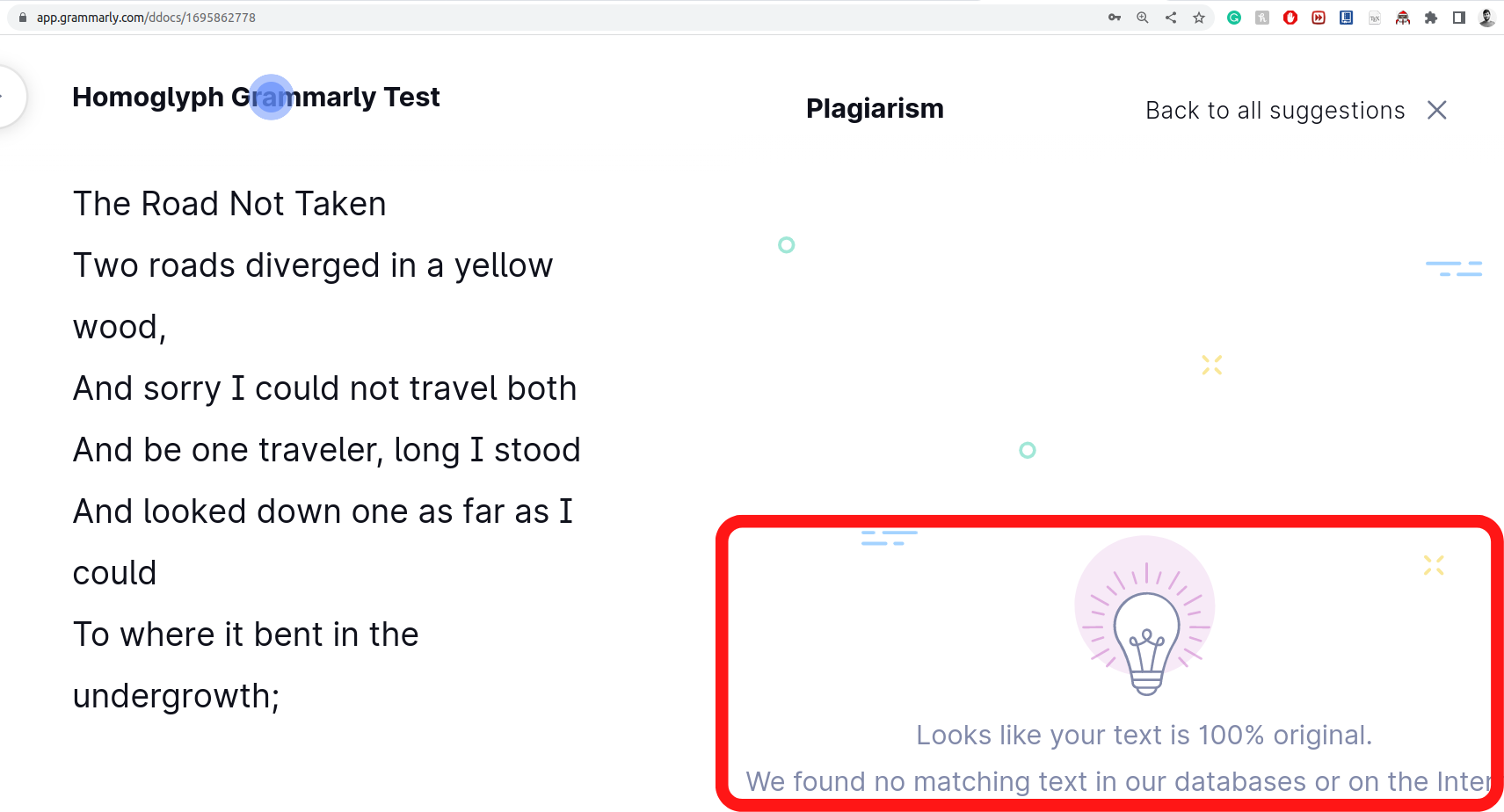
Cheng, L.; Liu, F.; and Yao, D. 2017. Enterprise data breach: causes, challenges, prevention, and future directions. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 7(5): e1211.
Chollet, F.; et al. 2015. Keras. Damerau, F. J. 1964. A technique for computer detection and correction of spelling errors. Communications of the ACM, 7(3): 171–176.
Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and FeiFei, L. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, 248–255. Ieee.
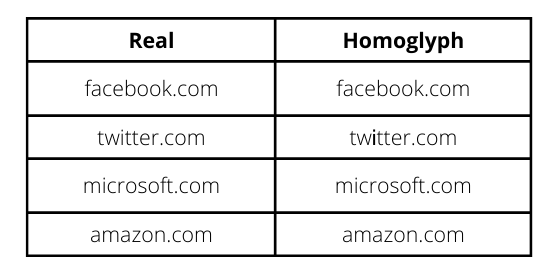
Ginsberg, A.; and Yu, C. 2018. Rapid homoglyph prediction and detection. In 2018 1st International Conference on Data Intelligence and Security (ICDIS), 17–23. IEEE.
Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; and Bengio, Y. 2014. Generative adversarial nets. Advances in neural information processing systems, 27.
He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, 770–778.
Helms, M. M.; Ettkin, L. P.; and Morris, D. J. 2000. The risk of information compromise and approaches to prevention. The Journal of Strategic Information Systems, 9(1): 5–15.
Hoffer, E.; and Ailon, N. 2015. Deep metric learning using triplet network. In International workshop on similarity-based pattern recognition, 84–92. Springer.
Hong, J. 2012. The state of phishing attacks. Communications of the ACM, 55(1): 74–81.
Isola, P.; Zhu, J.-Y.; Zhou, T.; and Efros, A. A. 2017. Imageto-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, 1125–1134.